| Peng Dai HKU |
Xin Yu HKU |
Lan Ma TCL |
Baoheng Zhang HKU |
Jia Li SYSU |
Wenbo Li CUHK |
Jiajun shen TCL |
Xiaojuan Qi HKU |
 |
| The left side shows moire video, and the right side is our demoired result that is clean and temporally consistent. |
Abstract
Moire patterns, appearing as color distortions, severely degrade the image and video qualities when filming a screen with digital cameras.
Considering the increasing demands for capturing videos, we study how to remove such undesirable moire patterns in videos, namely video demoireing.
To this end, we introduce the first hand-held video demoireing dataset with a dedicated data collection pipeline to ensure spatial and temporal alignments of captured data.
Further, a baseline video demoireing model with implicit feature space alignment and selective feature aggregation is developed to leverage complementary information from nearby frames to improve frame-level video demoireing.
More importantly, we propose a relation-based temporal consistency loss to encourage the model to learn temporal consistency priors directly from ground-truth reference videos,
which facilitates producing temporally consistent predictions and effectively maintains frame-level qualities.
Extensive experiments manifest the superiority of our model.
Documents
 |
"Video Demoireing with Relation-based Temporal Consistency", [Paper] [Code] [Data_v1] [Data_v2] [Slides] [Poster] [Presentation] |
Video
Framework
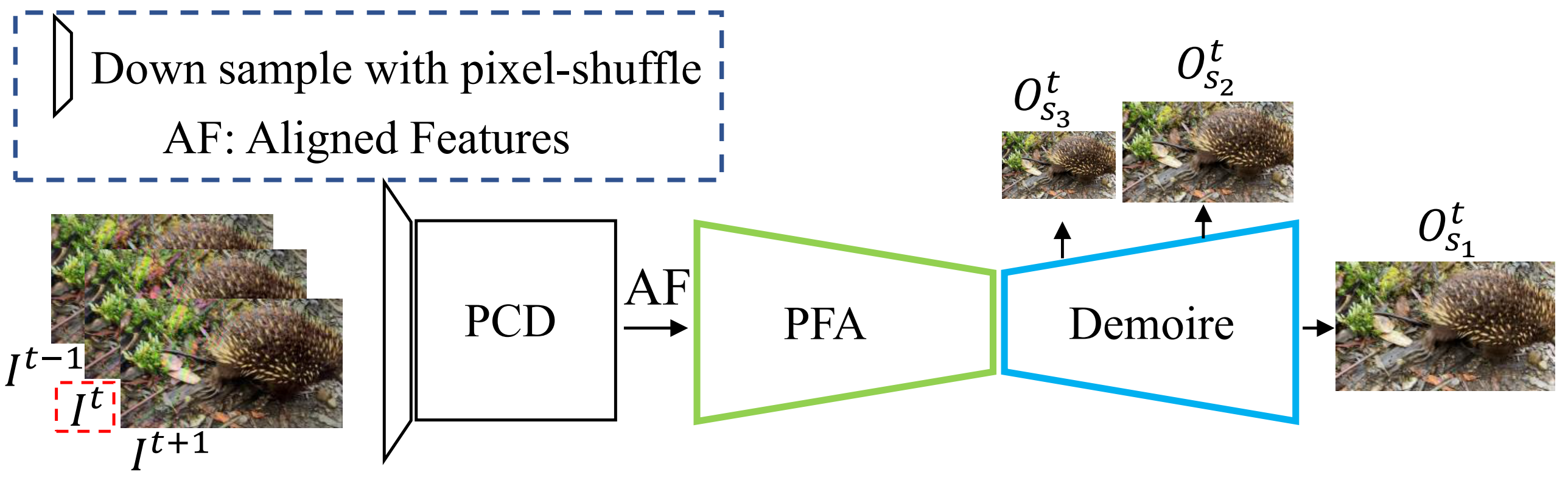 |
The overview of our method. Our video demoireing network mainly consists of three parts: First, the PCD takes consecutive frames as inputs to implicitly align frames in the feature space. Second, the feature aggregation module (PFA) merges aligned frame features (AF) at different scales by predicting blending weights. Third, the merged features are sent to the demoire model (Demoire) with dense connections to realize moire artifacts removal.
Dataset
 |
The pipeline of producing video demoireing dataset
Data_v1: it contains 290 videos (720P) of different scenarios, and each video has 60 frames. To capture moire videos, we adopt two types of equipment (i.e., Huipu v270 monitor + TCL20 pro mobile-phone, and MacBook Pro + iPhoneXR). The input moire frames and output clean frames are aligned with the homography matrix.
Data_v2: we refine the aligned frames in "Data_v1" using estimated optical flows (i.e., RAFT) and obtain better-aligned pairs.
Image Demoireing
If you want to realize ultra-high-definition image demoireing, please refer to our work in ECCV2022.
Last updated: July 2022